[아스키코드]
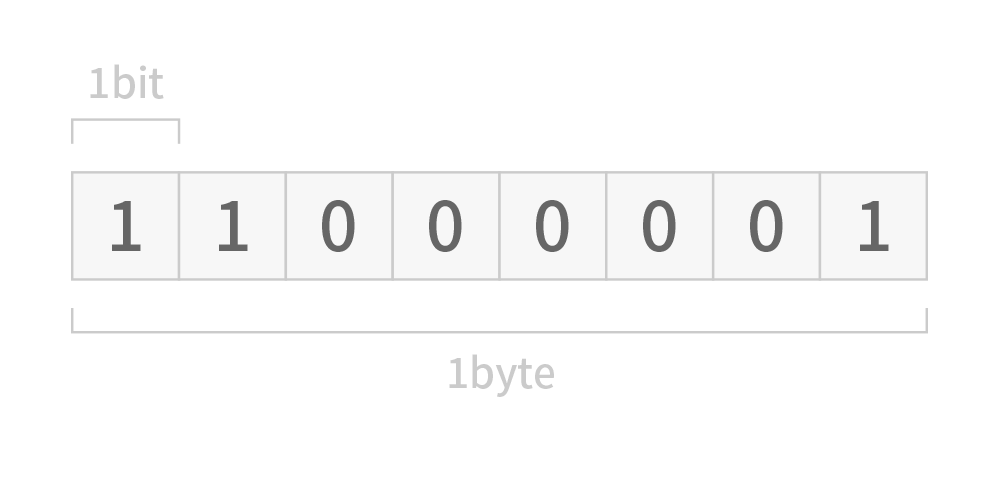
ASCII 코드에서 문자 1개는 1byte(8bit)를 할당받는다
1바이트는 (8비트) 0~255숫자를 가지고 있는데 ASCII코드에서 8비트를 다 사용하는것은 아니고 1비트는 오류검사용 (패러티비트parity bit) 으로 사용하여 총 7비트, 즉 0~127까지의 숫자를 문자로 변환해서 표기한다. 즉 문자는 각각 숫자값을 가지고있다는 것이다.
C언어에서는 문자를 표기할 때 char 을 사용해서 변수 선언을 하는데 이것은 정수형 변수를 선언을 할때도 공통으로 쓰이는 것이다. 즉 문자는 숫자와 같이 값을 가지고 있으며 연산도 가능하다
#include <stdio.h>
int main()
{
printf("%d %c\n", 'a'+1, 'a'+1);
return 0;
}
위의 코드와 이미지는 C에서 문자 'a' + 1 를 하고 결과를 출력한 것이다. ASCII코드에서 A는 10진수로 97이고 + 1을 하여 98의 값을 가진 b가 출력된 모습을 볼 수 있다
각 코드가 가지고있는 숫자값은 아래와 같다 (2진수 표기법으로 표시된 표)
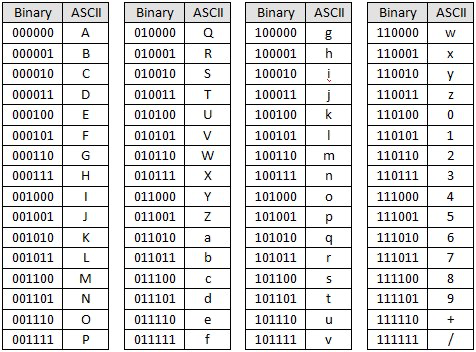
밑에 있는 표는 영문자 A를 아스키코드로 표현한 것이다. 하나의 문자는 1byte의 크기를 가지고 있으며 이런식으로 표기된다.
[유니코드]
그러면 유니코드는 무엇일까? 유니코드는 기존에 1바이트(8비트) 만으로는 표현할 수 없었던 한글,중국어,일본어 등등의 문자까지 표현할 수 있는 문자 표현 방식이다. 유니코드는 다양한 인코딩 방식이 있는데 그중 대표적이고 많이쓰이는 UTF-8에서 영어는 1Byte,한글은 3Byte 로 표현한다 즉,언어에 따라 할당받는 용량이 가변인 인코딩 방식이다.
유니코드는 16진수로 표기되는데 자주 쓰지 않는 숫자 표기법이라 뭔가 싶었지만 컬러코드를 표현할때 #FFFFFF (흰색)등의 코드를 쓰는것이 바로 16진수 표기법이다 FF 는 (16*16 인 256이 되겠고 ) FF,FF,FF는 2개 자리씩 끊어서 rgb로 표현된다
즉 #FFFFFF는 rgb (255,255,255) 와도 같은것이다. 즉 Reb,Green,Blue를 최대치로 섞으면 흰색이 나오는 것이다!
[입력의 역사]

ASCII코드에서는 줄바꿈, 케리지리턴 (시작으로 돌아감) 등등을 제어문자라고 한다. C언어를 공부할때 자주쓰는 코드들인데 이것들은 과거 타자기를 쓰던 시절으로 거슬러 올라가면 그 역사가 시작된다. \a 같은경우는 알람을 표시하는건데 타자기에서 울리는 띵! 소리에서 부터 나온것이며 \n은 타자기에서 종이를 위로 밀어서 줄바꿈(Line Feed)을 하는것이 그 역사이다.
위키백과 유니코드 관련 글
ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C
'나롱 > 개자인' 카테고리의 다른 글
| WEB : 파비콘 등록하기 (1) | 2023.10.04 |
|---|---|
| 코드업 1099 성실한 개미 문제 풀이 (0) | 2021.04.06 |
| 코드업 1369 빗금친 사각형 출력 (0) | 2021.03.05 |
| 이중 for문을 이용한 피라미드 출력 (0) | 2021.03.02 |
| SVG이미지에 대해 (0) | 2020.10.03 |


